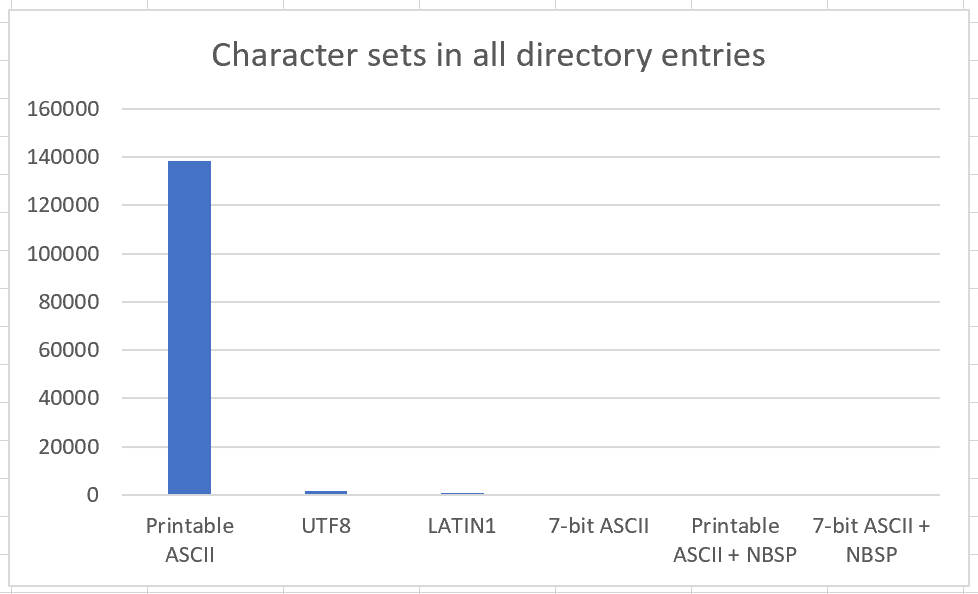
In the table, you can see that plain ASCII is the clear winner; almost every directory entry is printable ASCII characters (e.g., with no control characters, escape, DEL or any type of 8-bit character).
What are the others? UTF8 is about twice as popular as LATIN1 even though the Gopher spec is pretty clear that LATIN1 is the correct encoding. After that comes ASCII with some control characters.
The last two categories are a little weird: they represent ASCII, but some of the space characters are actually character 160, the LATIN1 "Non-breaking space" character. There were 41 entries where the text was otherwise perfectly ordinary ASCII characters.
Even more weirdly, the entries that were ASCII but included some kind of control character, the control characters are most often 1a (17), 7f (8) and 1b (5). I don't know why SUB and DEL are so popular. At least the 1b char (ESC) is understandable; it's used for fancy graphics.
There's often no way to automatically prove that a string is UTF8 or LATIN1. It is possible to prove that a string is not legal UTF8, but as we all know, sometimes strings are malformed, and what's supposed to be UTF8 is instead nearly or almost UTF8. What I do is to look at each string; if there are any characters with the 8th bit set, then I look to see if it's perfect UTF8. If it's not prefect UTF8, I assume that it's LATIN1.
Yes, there are other character sets in existence. I'm rather hoping that there aren't any in GopherSpace, because I'm not sure how I'd figure out which was which.
For C# programmers, I've learned two important things about UTF8 conversions. Firstly, many of the "Utf8 check" libraries are copies of each other and they have a common bug where if a buffer ends with a UTF8 sequence, the sequence is incorrectly flagged as being incorrect.
Secondly, the UWP Encoding.Utf8 has the pernicious habit of sometimes throwing on bad UTF8 sequences and sometimes not. I could understand them making a choice either way, but being in an in-between state is just plain programmer-unfriendly.
TL/DR: you have to handle UTF8 and LATIN1 char sets, and as a programmer, you have to double-check your conversion library.
No comments:
Post a Comment